Vertreter von Partneruniversitäten trafen sich im Oktober zu einem gemeinsamen Workshop an der TU Graz, um das Profil von Data Stewards zu definieren. Data Stewards sind Expert*innen im Bereich Forschungsdatenmanagement und bringen ihre Expertise in die Organisation ein. Die Rolle wird an österreichischen Hochschulen neu etabliert.
Eckdaten
Datum: 21. Oktober 2020
Ort: Augartenhotel, Graz
Zeit: 10-18:00
TeilnehmerInnen: Ilire Hasani-Mavriqi (TU Graz), Sarah Stryeck (TU Graz), Tony Ross-Hellauer (TU Graz), Hermann Schranzhofer (TU Graz), Elisabeth Rieger (TU Graz), Stefan Reichmann (TU Graz), Susanne Blumesberger (Uni Wien), Barbara Sanchez (TU Wien), Christiane Stork (TU Wien), Eva-Maria Asamer (TU Wien), Peter Schaffer (MedUni Graz), Caroline Auer (MedUni Graz), Therese Macher (MedUni Graz)
Programm
10.00 – 10.15 Welcome & Vision Statement
10.15 – 10.30 Zusammenfassung IST Analyse
10.30 – 11.00 Data Steward Landscape Studien
11.00 – 11.30 Vorstellung & Diskussion – Data Steward Modellen
11.30 – 11.50 Kaffeepause
11.50 – 13.00 Einführung Research Data Lifecycle & Gruppenarbeit – Aufgaben eines Data Stewards
13.00 – 14.10 Mittagspause
14.10 – 15.15 Präsentation/Zusammenführung – Data Steward Tasks; Gruppenarbeit Mapping zwischen Modellen und Tasks
15.15 – 15.45 Kaffeepause
15.45 – 16.45 Präsentation, Diskussion & Zusammenfassung Gruppenarbeit – Modelle
16.45 – 17.00 Lüftungspause
17.00-17.40 Reflexionsrunde, Vorteile, Nachteile – Data Stewards-Modelle
17.40 -18.00 Abschlussrunde & Closing
Ziele des Workshops und Programm
Data Stewards stellen das organisationale Korrelat zum Data Management dar. Sie schultern das Gros der mit Research Data Management (RDM) einhergehenden Beratungstätigkeiten und bringen entsprechend umfassendes Wissen in eine Organisation ein. Entsprechend stellt die Entwicklung und Festschreibung eines Anforderungsprofils für Data Stewards einen wesentlichen Bestandteil von Arbeitspaket 5 des FAIR Data Austria Projektes dar. In ihrer Rolle als Leiterin dieser Aufgabe hat die TU Graz einen Workshop mit allen ProjektpartnerInnen organisiert. Dieser fand am 21. Oktober 2020 in Graz im Augartenhotel statt, war also als face-2-face-Veranstaltung konzipiert. Vertreter der Universität Wien, der TU Wien und der Medizinischen Universität Graz nahmen persönlich teil. Zwei weitere ProjektpartnerInnen, die Universität Innsbruck und die Akademie der bildenden Künste Wien, leisteten Corona-bedingt ihren Beitrag im Voraus. Ziel der von Elisabeth Rieger moderierten Veranstaltung war es, ein gemeinsames Verständnis der Rolle und Aufgaben einer/s Data Stewards in verschiedenen institutionellen Kontexten zu entwickeln.
Überblick über den Workshop
Nach einer kurzen Einführung ins Thema durch Tony Ross-Hellauer (Entwicklung einer Vision), Ilire Hasani-Mavriqi (Vorstellung internationaler Arbeiten zum Thema, Erläuterung von 3 Data Stewardship-Modellen) und Stefan Reichmann (Vorstellung einer Umfrage an österreichischen Universitäten zum Thema Data Stewardship, Zielen und Ausgangslage) mussten die TeilnehmerInnen in drei Gruppen an der Ausarbeitung der drei Data Stewardship-Konzepte arbeiten. Die auf diese Art erarbeiteten Ergebnisse wurden dann im Plenum diskutiert und weiter konkretisiert. Als Leitfaden für den gesamten Workshop diente uns eine Eingangs durch Elisabeth Rieger präsentierte Übung, in deren Rahmen alle TeilnehmerInnen gebeten wurden, sich auf einem Spektrum – das durch eine im Raum gespannte Schnur symbolisiert wurde – zu positionieren, je nachdem, wo “ihre” Universität gemäß eigener Einschätzung beim Thema Data Stewardship gegenwärtig steht. Im Laufe des Workshops sollten die TeilnehmerInnen noch zweimal auf diese Linie zurückkehren, um festzustellen, ob und wie sehr sich ihre Einschätzung durch die gemeinsame konzeptionelle Arbeit verändert hatte.

Gruppenarbeit: Was heißt Data Stewardship?
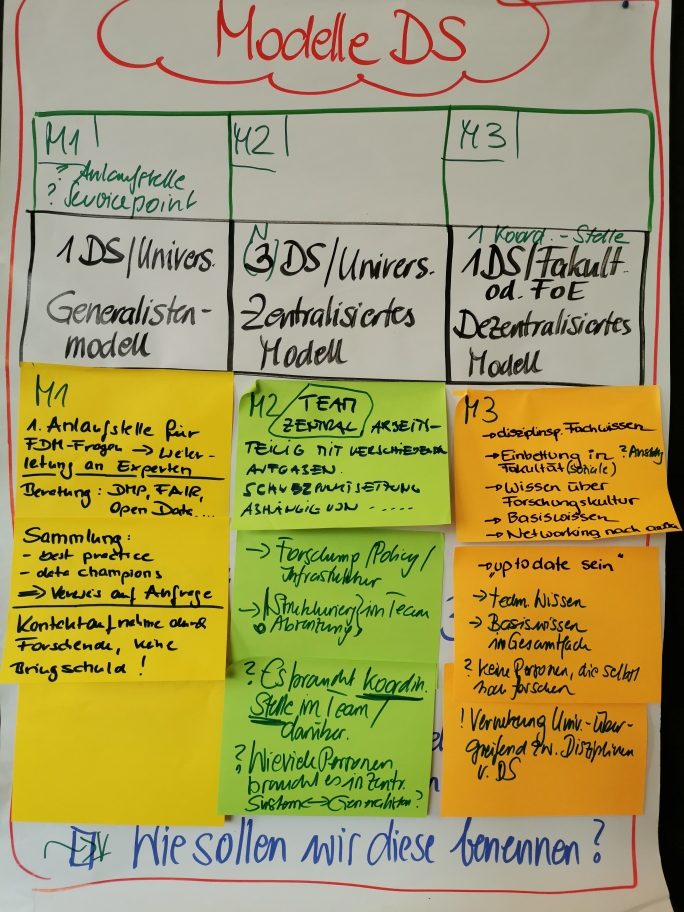
Im interaktiven Teil des Workshops hatten die TeilnehmerInnen zwei verschiedene Gruppenarbeiten in wechselnden Gruppenzusammensetzungen zu bewältigen. Im Rahmen der ersten Aufgabe ging es darum, in der Gruppe je ein Data Stewardship-Modell zunächst inhaltlich zu konkretisieren und dann im Plenum zu präsentieren mit dem Ziel, eine Toolbox zur Implementierung von Data Stewards für Forschungseinrichtungen zu entwickeln. Die zur Diskussion gestellten Modelle lassen sich wie folgt zusammenfassen:
Modell 1 (generisch): Ein Data Steward pro Universität
Modell 2 (zentralisiert): Bis zu drei Data Stewards pro Universität
Modell 3 (dezentralisiert): Ein Data Steward pro Fakultät oder Field of Expertise
Die TeilnehmerInnen hatten die Aufgabe, die drei Modelle auf Basis der folgenden Fragen zu diskutieren:
Stimmen wir mit diesen 3 Modellen überein? Fehlt aus unserer Erfahrung ein wesentliches Modell?
Sollen wir die 3 Modelle in der Toolbox weiter verfolgen?
Wie sollen wir diese Modelle benennen?
Die WorkshopteilnehmerInnen waren sich schnell einig, dass die drei Modelle ausreichend trennscharf für die Problemstellung sind und daher im Rahmen einer Data Stewardship-Toolbox Verwendung finden können, bei der Benennung allerdings noch etwas nachzuschärfen wäre. Außerdem dürften diese Modelle in den meisten Fällen in unterschiedlichen Anteilen, jedenfalls aber mehr oder weniger gleichzeitig ausgeprägt, zum Einsatz kommen.
Modell 1 lässt sich auf Basis der Diskussionen in der Gruppe und im Plenum so charakterisieren, dass Data Stewards als Schnittstelle für RDM-Fragen aufgefasst werden; Data Stewards dieses Zuschnitts leiten Anfragen weiter, vernetzen, bieten allgemeine Beratung an, machen aber kein operatives Datenmanagement an den Instituten. Vorgeschlagener Name für dieses Modell: Anlaufstelle oder Servicepoint.
Modell 2 beschreibt gewachsene Strukturen, wie sie derzeit bereits öfter zu finden sind und wie sie sich bspw. aus Repositorien entwickelt haben. Charakteristisch ist eine mehr oder weniger zentrale Organisationseinheit, die unterschiedliche Kompetenzen bündelt und entsprechende Services/Beratungen anbietet; die Kompetenzen sind breiter, da auf mehrere Personen aufgeteilt. Die TeilnehmerInnen einigten sich, dieses Modell als Data Steward Stelle oder Office zu benennen.
Modell 3 schließlich sieht an den Fakultäten, Forschungsschwerpunkten oder Instituten angesiedelte Data Stewards vor, die über entsprechend fundiertes disziplinspezifisches Wissen/Forschungserfahrung verfügen sollten und daher besonders disziplinspezifisch beraten können. Diese Data Stewards sollen von einer zentralen Stelle koordiniert werden. Unklar blieb allerdings, wie weit Data Stewards in diesem Modell noch selbst in Forschungsaktivitäten eingebunden sein sollen. Vorgeschlagener Name für dieses Modell: Data Stewards Netzwerk.
Data Stewards im Kontext des Data Lifecycle
Im Rahmen der zweiten Gruppenarbeit ging es darum, die Aufgaben eines Data Stewards anhand des etablierten Instruments des Data Lifecycle zu konkretisieren. Zunächst wurde festgehalten, dass Data Management alle konkreten, operativen Aufgaben innerhalb eines Forschungsprojekts betrifft (und daher über weite Strecken Aufgabe der ForscherInnen selbst ist), während Data Stewardship eher beratende und planende Tätigkeiten im Vorfeld bezeichnet.
Ein wesentliches Resultat dieser Gruppenarbeit ist, dass Data Stewards über den gesamten Data Lifecycle hinweg vor allem eine beratende Funktion zukommt, sei es zum Thema Data Management Plan (DMP) im Vorfeld eines Forschungsprojektes, zu Fragen der Datenaufbereitung, Archivierung und Dissemination, aber auch Nachnutzung. Daneben erfüllen Data Stewards eine wichtige Schnittstellenfunktion und kommunizieren Anforderungen der Forschung an andere Organisationseinheiten (z.B. Informatikdienste). Uneinigkeit bestand darin, wie die Tätigkeit des Data Steward von der des Data Manager sauber zu trennen sei; vielfach brauche es neben der konkreten fachlichen Beratung auch eine organisatorisch-koordinierende Funktion, die eher dem Data Management zugerechnet wurde.
Nächste Schritte
Die TU Graz erarbeitet derzeit einen Bericht zu den Ergebnissen des Workshops, der bis Mitte November vorliegen und dann allen Projektpartnern zur Durchsicht und Kommentierung übergeben wird. Der fertige Bericht wird dann als Projektergebnis veröffentlicht und für alle Interessierten einsehbar sein.